Después de analizar los objetivos y beneficios de la normalización de datos, te explicamos los tipos de esta.
Las bases de datos pueden clasificarse por su nivel de normalización donde, el nivel 1 es la forma más básica y simple de normalizar datos, hasta alcanzar la más sofisticada de todas. Aquí te dejamos las tres principales, y las más recomendadas por los expertos.
#1 FN: Elimina duplicados y crea tablas separadas para grupos de datos relacionados
#2 FN: Elimina subgrupos de datos en múltiples filas de una tabla y crea tablas nuevas, que se relacionan entre si.
#3 FN: Elimina las columnas que no dependen de la clave principal
Y como te podrás imaginar, los requisitos para cumplir con cada nivel de normalización van a ir dependiendo de la complejidad de la información, no obstante, esto no quiere decir que sea lo mejor para todas las empresas. Crear estrategias y objetivos será clave para poder definir el proceso de gestión de datos y las reglas específicas para tu empresa.
Ahora, ¿Cómo abordar el proceso de normalización de bases de datos?
Este proceso se lleva a cabo para lograr una base de datos en estado óptimo. Para esto es necesario primero, combinar los datos existentes en los grupos. Y segundo, para aclarar las relaciones lógicas entre los grupos, garantizando exactitud de los vínculos.
La normalización supone el uso de formas normales (FN) con respecto a la estructura de datos disponibles. Todas las formas, exceptuando la primera, suponen que la forma anterior ya está realizada y validada, es por esto que es fundamental partir desde lo más básico, e ir complejizando la estructura de la información.
La normalización de datos permite que el análisis de la información sea óptimo, por esto necesitamos datos lo más limpios posible para sacarles el máximo rendimiento. Los datos en sus etapas más tempranas sueles estar sucios, incompletos, inconsistentes y están llenos de errores. Aquí te dejamos 3 técnicas mundialmente conocidas para el procesamiento de datos:
- Data cleaning: Limpieza de datos, eliminando el ruido de la maestra, resolviendo las inconsistencias entre los datos.
- Data integration: Cuando manejamos un alto volumen de información, los datos migran a fuentes de información que centralizan las empresas, estos se llaman Data Warehouse.
- Data transformation: la transformación de los datos permite normalizar datos de cualquier tipo.
El objetivo principal de los datos limpios es que finalmente, sean utilizables. Por ejemplo, esperamos que tomando datos como: número, num, nro, n° o #, sean normalizados en una sola regla que podría ser “número” en todos los casos, para todos los productos. Y como hay mucho contenido, y muy académico para este tema, vamos a dar algunos datos sobre los tres primeros, que son los más relevantes y sencillos de visualizar.
1 FN – Primera Forma Normal
Una tabla está en primera forma normal si:
- No existen filas repetidas.
- Todos los atributos son atómicos, simples e indivisibles.
¿Puedes ver los errores de esta maestra?

Si no, aquí te mostramos algunos:

La filas que están marcadas en rojo son el mismo SKU pero repetido, por lo que no es necesario tenerlo 3 veces, si no más bien, tomarlo una vez con variantes. Por otro lado, las celdas en azul pueden dividirse, ordenando los datos en atributos diferentes. Además, en letras rojas tenemos errores simples de escritura que generan ruido en la lectura de la información.
El resultado de la primera parte sería así:

2 FN – Segunda Forma Normal
Una tabla está en segunda forma normal si:
- Cumple con las reglas de 1FN.
- Todos los atributos que no forman parte de la clave principal*, tienen dependencia funcional** completa de ella.
*Clave principal: es un conjunto de 1 o más columnas que identifican de manera única, y no repetida, una fila.
**Dependencia funcional: Es una relación de implicancia entre 2 columnas, si cambio la independiente, cambia la dependiente.
Cuando identificamos la clave principal, suele ir de la mano con la identificación de columnas dependientes. La pregunta aquí sería: Si cambio el valor de esta columna, ¿Qué otras columnas deben cambiar de valor?. Si cambio el SKU, cambio el nombre y el tipo de producto. Lo mismo para la categoría, si cambio la categoría, también lo harán los tipos de productos que tengo disponibles.
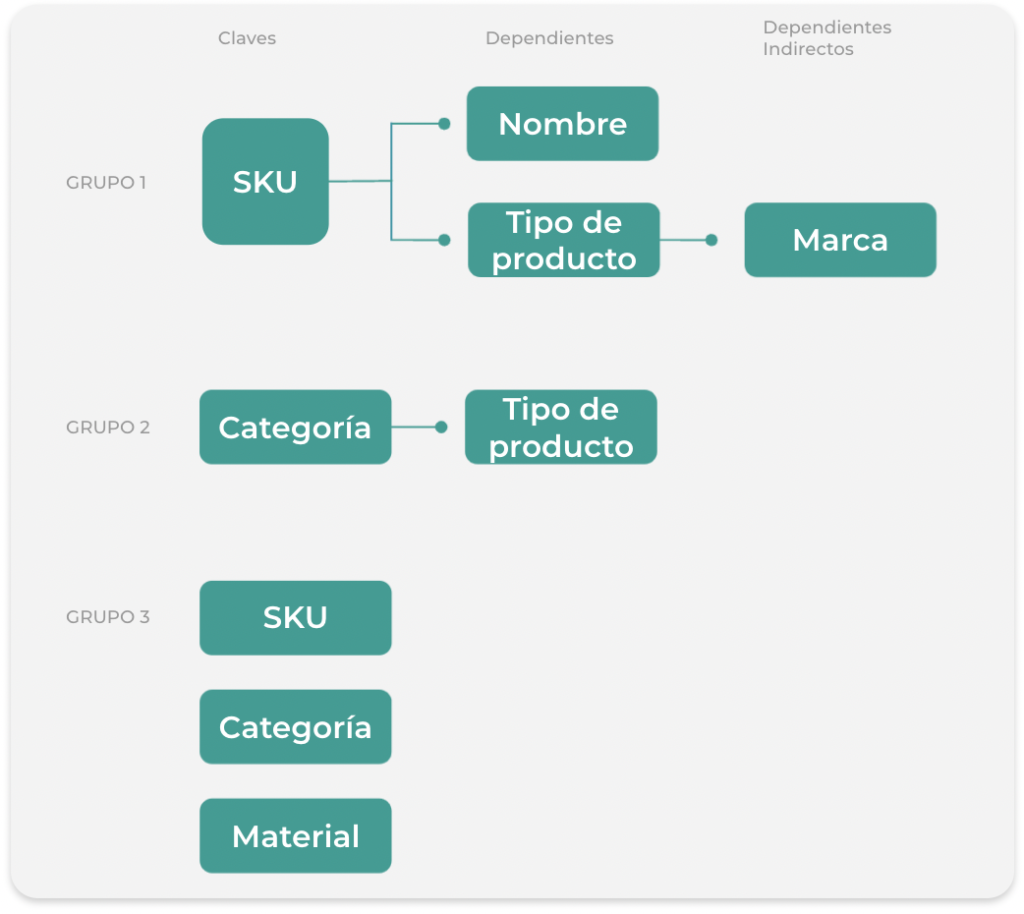
3 FN – Tercera Normal
Una tabla está en tercera forma normal si:
- Cumple con las reglas de 2FN
- No hay dependencias transitivas***
*** La dependencia transitiva es cuando una columna depende de otra, pero que no es clave principal. Por ejemplo, el tipo de producto depende de la categoría, y la categoría depende de la marca. Para esto se crea una nueva tabla con una nueva clave principal que incluiría todos los campos dependientes. El resultado sería así:
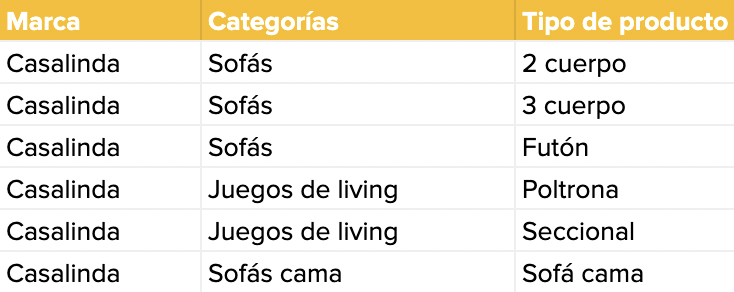
En conclusión, la normalización de bases de datos es un proceso bien definido que nos permite ordenar la información y mantener su calidad siempre al 100%. La normalización que se sugiere es hasta la de 3FN, sin embargo, es importante ir incluyendo más detalle en las estructuras, a medida que la empresa va necesitando ir complejizando el orden de la información que maneja (y su volumen).
Te gustaría normalizar tu maestra de datos, ¿pero no sabes cómo empezar?. Escríbenos a sales@brandnlabel.com y nosotros podemos ayudarte. Dándote una asesoría, o presentándote todos nuestros servicios.